Pipeline — Step 2
Raw text becomes machine intelligence. Every document is split into meaningful segments and mapped into a 768-dimensional vector space — all on dedicated GPU hardware.
Why Chunking Matters
An AI that searches entire documents returns vague answers. An AI that searches precise, semantically meaningful chunks returns the exact paragraph you need.
CorpusAI uses sliding-window chunking with 600-token segments and 50-token overlap. Chunk boundaries respect paragraphs and headings — so a legal argument never gets split mid-sentence.
The result: when you ask a question, the retrieved context is tight, relevant, and citation-ready.
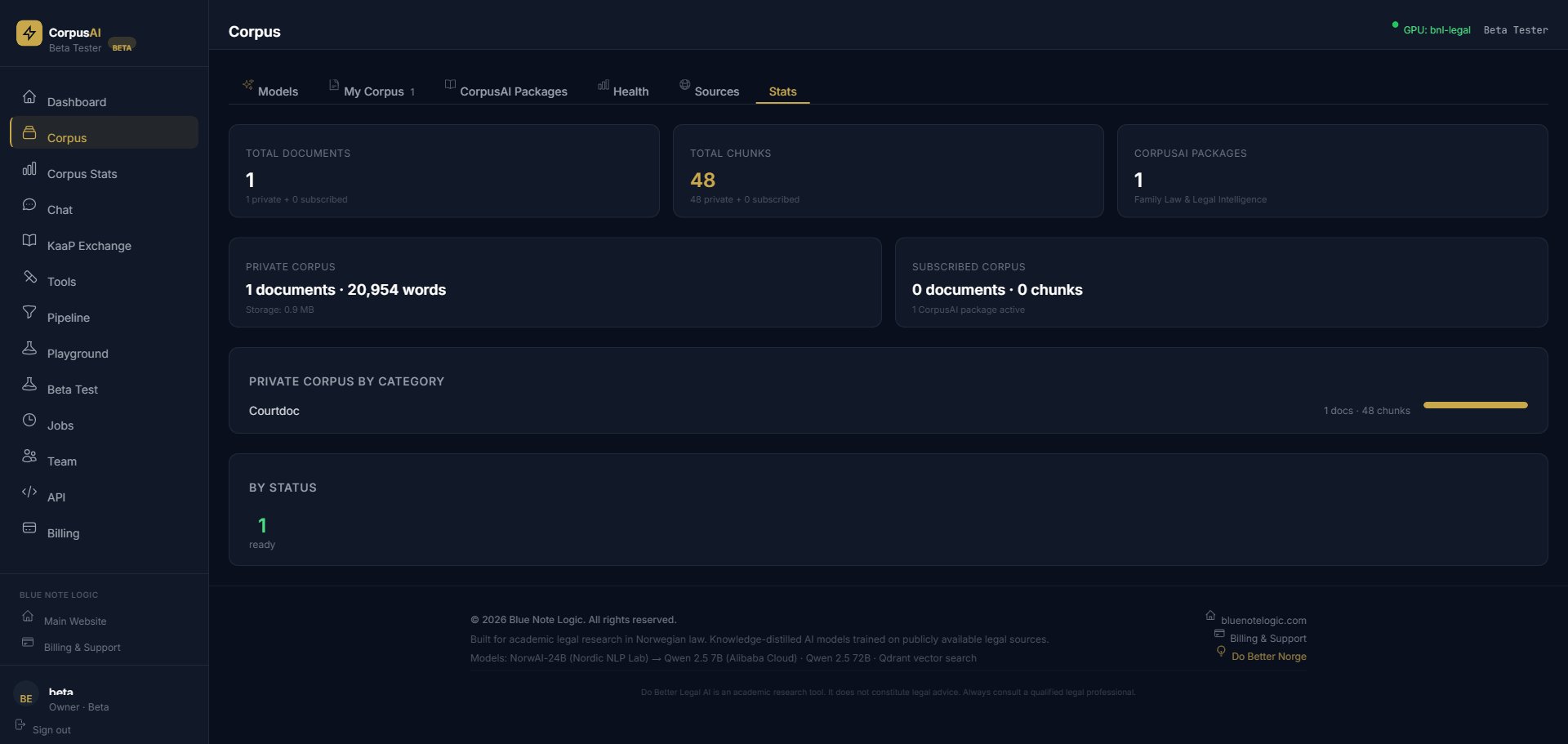
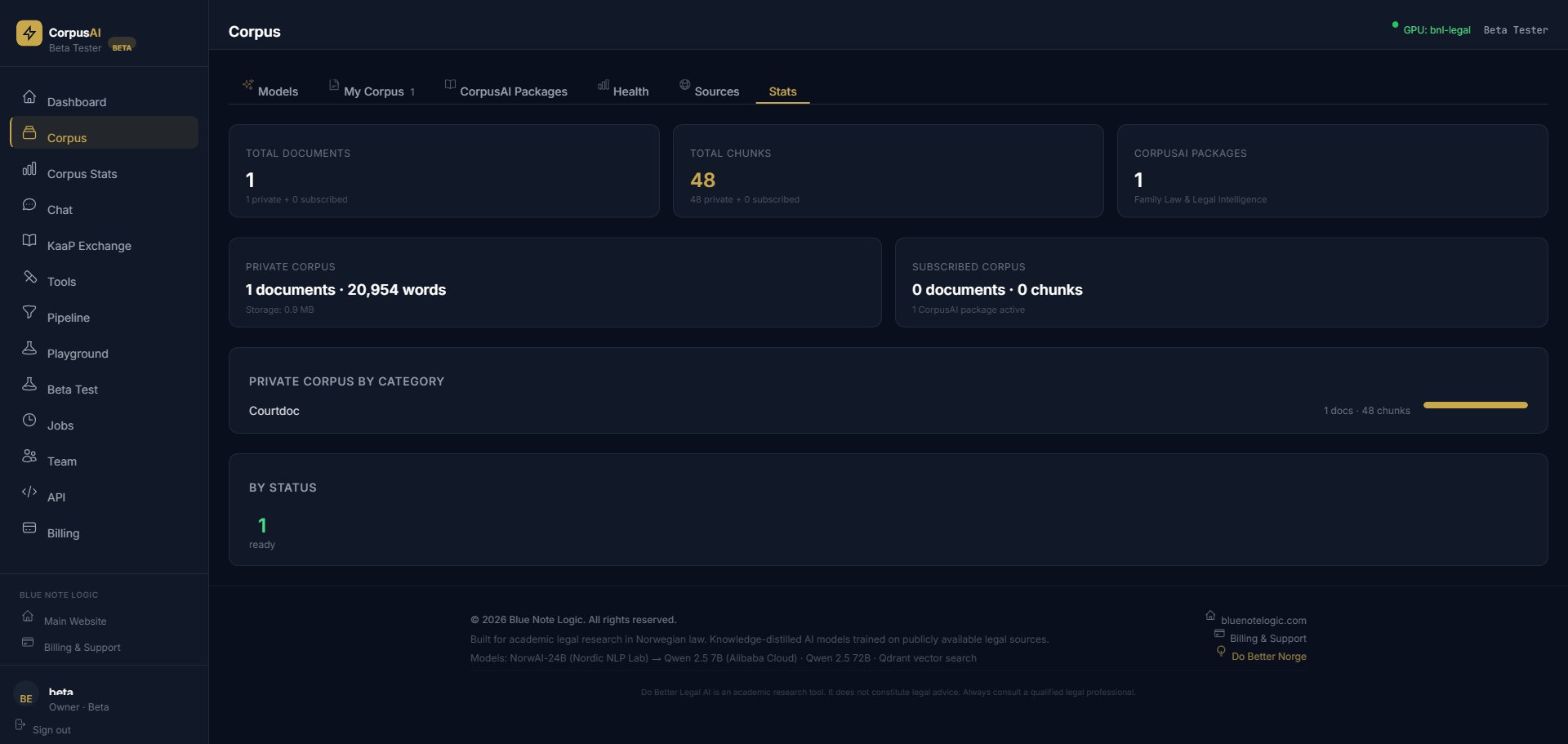
Real Numbers
Our Norwegian Family Law corpus demonstrates what the pipeline produces at scale.
Vector Embeddings
Every chunk is converted into a 768-dimensional vector using embedding models running on our NVIDIA RTX PRO 6000 GPUs. These vectors capture meaning, not just keywords.
This is why "custody rights when parents disagree" finds paragraphs about barneloven § 36 even though those exact words never appear. The vectors know they mean the same thing.
Every chunk carries its parent document's metadata: category, jurisdiction, authority, date, and tags. When you filter by "ECHR Case Law" or "Family Law", the system narrows to those chunks before vector search even begins.
In the Family Law corpus, this means 22 categories — from Child Abduction (7,692 chunks) to ECHR Case Law (7,956 chunks) — each instantly filterable.
Next in the Pipeline
Your documents are chunked and embedded. Now it's time to find the exact passages that answer your question.