Pipeline — Step 1
Upload any file your business produces. We parse every format, extract every word, and prepare it for intelligence. This is where your AI starts learning.
The Problem
Your organization produces hundreds of documents every month — contracts, reports, regulations, correspondence. Each one contains knowledge that could help someone else in your team, but finding the right paragraph in the right document is a needle-in-a-haystack problem.
Traditional search finds keywords. CorpusAI understands meaning. The difference is the gap between "searching for documents" and "asking questions and getting answers."
It starts with a single upload.
The Blue Note Difference
Other platforms accept files. We understand them. Every document goes through a multi-stage pipeline that extracts maximum intelligence from every page.
PDF, DOCX, XLSX, TXT, HTML, Markdown. Scanned documents use two-stage OCR: pdftotext first, Tesseract fallback. No document left behind.
Attach author, tags, publication date, category, and source URL to every document. Metadata acts as pre-filters — so "show me custody rulings from 2023" narrows results before search even starts.
Upload 50 files at once via drag & drop, or integrate with your systems via REST API. Either way, processing is parallel and real-time — watch each file progress through parse, chunk, embed, index.
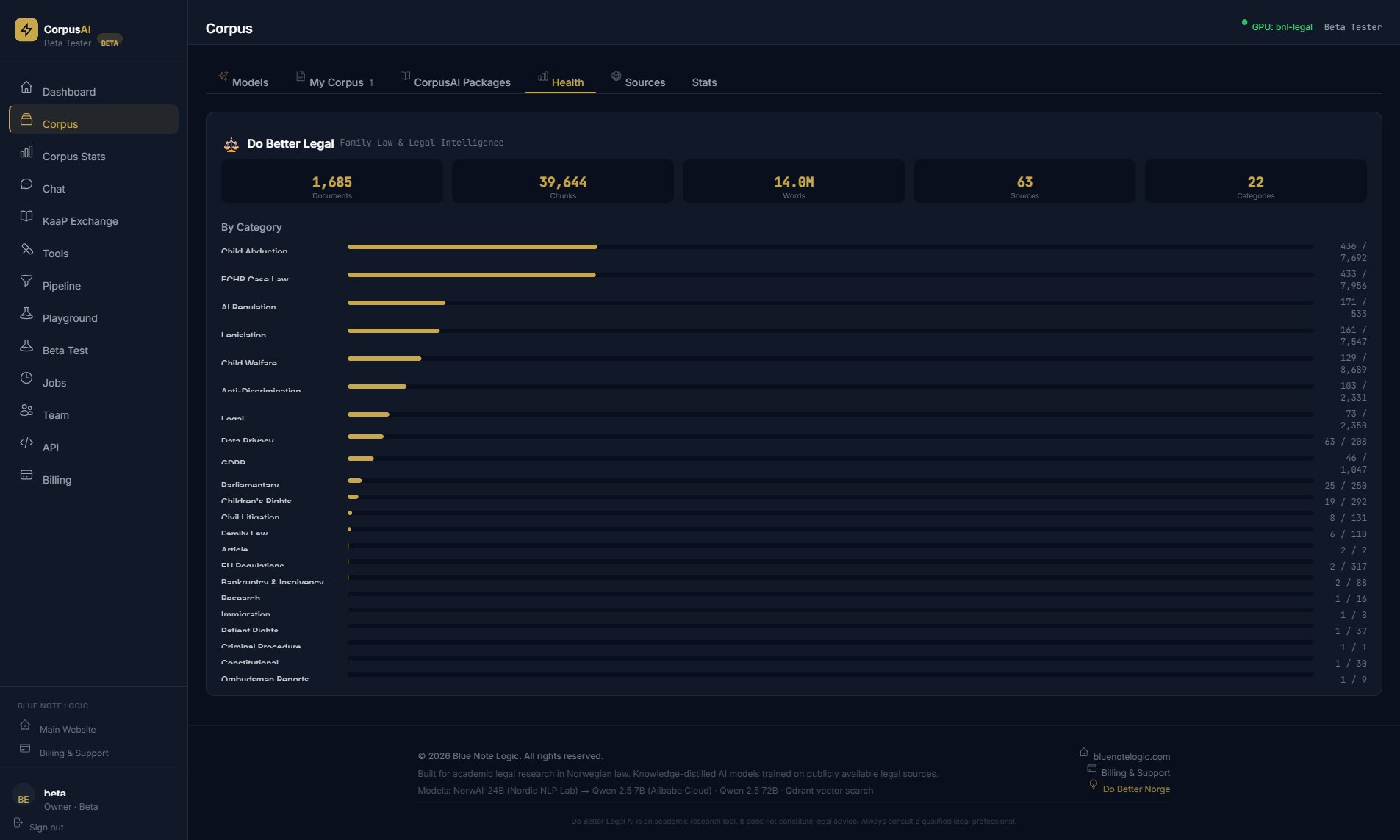
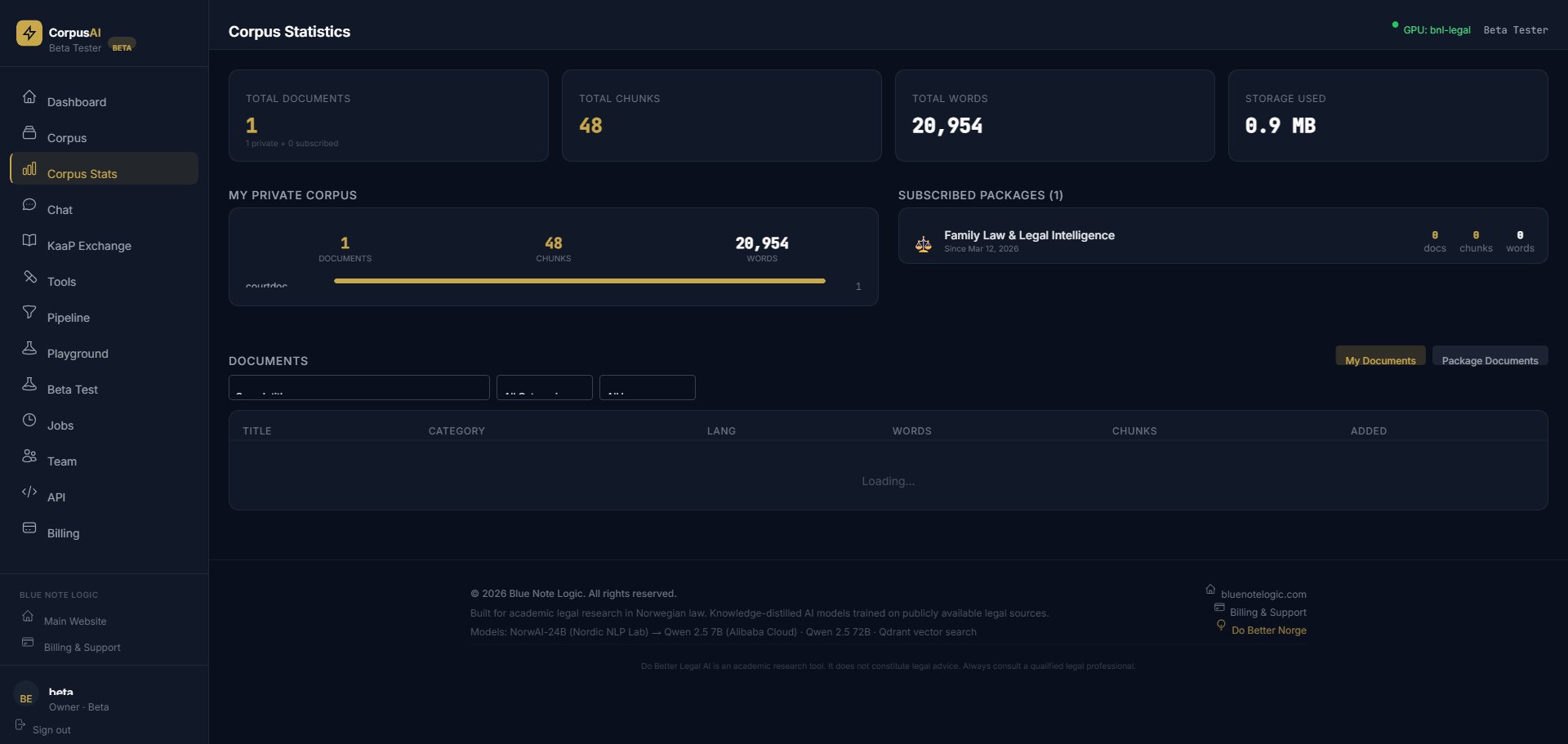
After Upload
The moment your documents are indexed, the Corpus Statistics dashboard lights up. You see exactly how many documents, chunks, and words your AI has to work with.
Every file you upload is stored on dedicated EU bare-metal servers. No cloud provider sits between you and your data. No API call sends your content to a US-based AI service. Full GDPR Article 28 compliance by design.
Next in the Pipeline
Your documents are parsed. Now they need to be split into meaningful segments and converted into vectors. That's where the intelligence starts.